Introduction:
While there are some effective ways for conducting AI research in a more traditional fashion, it is critical to keep up with the rapid advances in machine learning and AI, such as data updates, model changes, and code adjustments. This is where Git comes into play; it serves as a quiet answer to these complexities, much like a trusted conductor in the midst of chaos. Our goal in this guide is to teach you how to effectively use Git into your AI projects. Ready to roll up your sleeves and dive in? Let’s go!
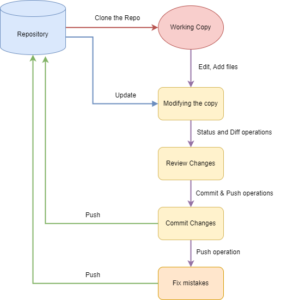
General Life-Cycle Diagram of Git:
Step-by-Step Content:
- Getting Started with Your Repository:
- Begin by organizing your project’s repository. Create directories for your code and data.
- Use .gitignoreto exclude bulky files and directories that are not required to be tracked.
- Start by creating a new Git Repository in GitHub or GitLab. In this tutorial, we will be using GitHub Repository.
- Give it a meaning full name, and decide whether it is going to be a public or private

- Now clone the remote repo to your local/ connect your local git repo to the remote repo.
git clone <repository-url> or git remote add origin <repository-url>.
- Tracking Changes in ML Models:
- Keep your model code, configurations, and experiment scripts within your repository.
- Utilize Git tags or branches to mark significant milestones in your model development journey.
- Create directories for code (src/) and data (data/) components for your project using
mkdir src data. - Add a .gitignorefile to exclude unnecessary files and directories – touch .gitignore.
- Create a Python script for training a basic ML model (py) within the src/ directory.
# train.py
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Load data
data = pd.read_csv(‘data/dataset.csv’)
# Preprocess data
X = data[[‘feature1’, ‘feature2’]]
y = data[‘target’]
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = LinearRegression()
model.fit(X_train, y_train)
# Evaluate model
score = model.score(X_test, y_test)
print(“Model R^2 Score:”, score)
- Add the script to the repository and commit the changes.
git add src/train.py
git commit -m “Add script for training ML model”
- Managing Dataset Versions:
- Version control your datasets to maintain reproducibility in model training.
- Add a sample dataset (csv) to the data/ directory.
- You can get a sample dataset from the internet or Kagglebased on requirements or create your own.
- Sample dataset we used in the demo: csv
- Add the dataset to the repository and commit the changes.
git add data/dataset.csv
git commit -m “Add sample dataset for model training”
- For large datasets, consider using Git LFS to manage them efficiently.
- To install Git LFS: git lfs install.
- To track large files git lfs track “*.psd”, git add .gitattributes.
- Then Commit and push the files using Git LFS
git add file.psd
git commit -m “Add design file”
git push origin main
- Collaborating on Model Development:
- Embrace Git branches to collaborate effectively. Create separate branches for different features or experiments.
- Regularly merge changes from these branches into the main one to keep everyone updated.
- Create a new branch (feature-branch) for experimenting with a new feature.
- Make changes to the pyscript, such as adding a new preprocessing step.
- Merge the changes back into the main branch (masteror main).
git checkout -b feature-branch
# Make changes to train.py
git add src/train.py
git commit -m “Add new preprocessing step”
git checkout master
git merge feature-branch
- Tracking Experiments:
- Implement experiment tracking using tools like MLflow or Neptune.ai. This allows you to record important details like hyperparameters and metrics.
- Seamlessly integrate these tracking tools with Git to correlate model performance with code changes.
- Install and configure MLflow for experiment tracking.
- pip install mlflow
- Update the train.py script to log experiments using MLflow.
# train.py
import mlflow
import mlflow.sklearn
# Log experiment parameters
mlflow.log_param(“model”, “Linear Regression”)
mlflow.log_param(“test_size”, 0.2)
# Log model metrics
mlflow.log_metric(“R^2 Score”, score)
# Save model
mlflow.sklearn.log_model(model, “model”)
- Deploying Models with Confidence:
- Create deployment scripts if needed and configurations in a separate directory (deployment/).
- Use Git to manage deployment pipelines and configurations.
- mkdir deployment
- git add deployment/
- git commit -m “Add deployment scripts and configurations”
- Documentation and Team Collaboration:
- Document your model architecture, data preprocessing steps, and performance metrics within your repository.
- Establish clear guidelines for collaborating with your team, reviewing code changes, and updating documentation.
- Update the README file with project details, instructions, and guidelines for collaboration.
- Share the repository with team members and establish clear communication channels.
- nano README.md
- git add README.md
- git commit -m “Update README with project details”
- Push the changes to remote repo:
- After completing the changes in the source files, push the updated files to the remote repo in GitHub or Gitlab.
- git remote add origin <repository-url>
- git branch -M main
- git push -u origin main
- Now we can find the updated files in our GitHub Repo.

Conclusion:
Becoming adept with Git in AI development can help shift the game of AI and machine learning development. With these methods, Git fits seamlessly into your workflow, significantly simplifying your development process. Collaboration improves, and the confidence in model reproducibility grows. Remember that Git is more than just a tool; it is a reliable ally as you navigate the unexpected twists and turns of AI development.